之前拆包看了只狼的狮子猿的一阶段动画,本文则会对怪物的AI进行一些讨论和分析,并对之前文章的一些错误结论进行勘误。
本文的目标是以狮子猿一阶段成熟完备的AI为例子,让读者能对动作游戏中AI的设计有一个初步的理解,并分析一些对实际工作中设计有启发的逻辑细节。本文会分为三个部分:初步的体验反推、拆包后对主AI分析的架构设计、以及细节和感受分析和讨论。
拆包看狮子猿AI设计
相关阅读
事后在网上搜了相关主题的文章,已经有大量有价值的文章了,本文的突出特点是直达实现本质、体验分析不足,可以阅读下面的文章用作参考:
初步的体验反推
首个尝试,使用挑选一段战斗序列进行反推的古典方式,初步分析一些关于节奏和感受的结论。
和狮子猿录了一段素材,用肉眼将动作与之前的状态机进行匹配,得到了如下的结果:
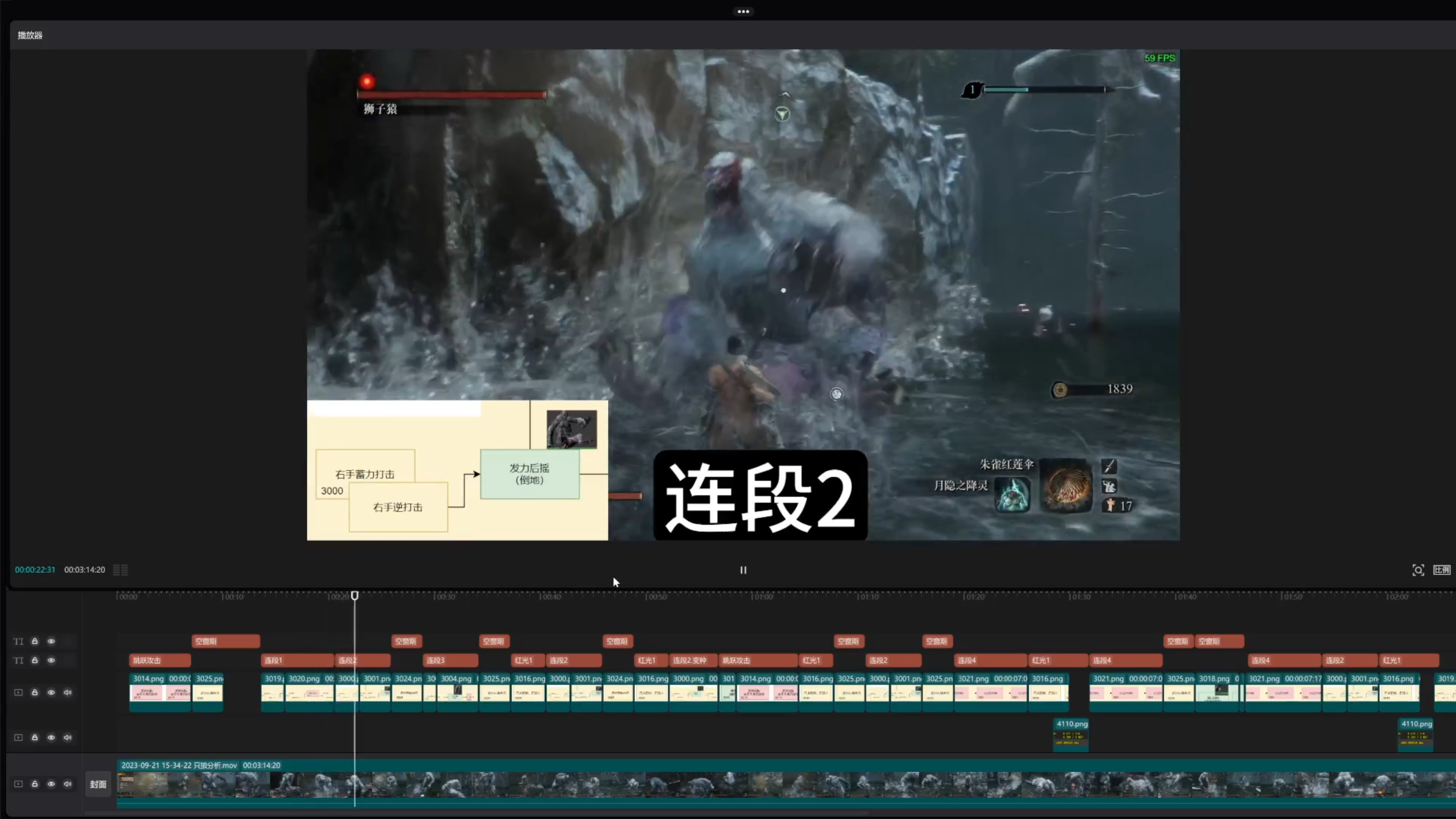
全程视频可参考:Bilibili 笨办法
其中的标注和动画状态机对应如下表所示:
| 标注 | 类别 | 动画 |
|---|---|---|
| 连段1 | 花里胡哨类 | 3019;3020 |
| 连段2 | 花里胡哨类 | 3000;3001 |
| 连段2.变种 | 花里胡哨类 | 3000 |
| 连段3 | 花里胡哨类 | 3003;3004 |
| 连段4 | 花里胡哨类 | 3021 |
| 跳跃攻击 | 记忆点类 | 3014 |
| 红光1 | 记忆点类 | 3016 |
| 空窗期 | 表演类 | 四方向闪避位移 |
| 空窗期 | 表演类 | 原地吼,3018 |
交错比例与招式CD
从这个视频中我们可以得出一些初步的结论:
- 攻击与空隙交错,比例是?

大体上,狮子猿会维持如上图所示【攻击,空窗期】这样的单元重复,以此营造出凶猛进攻和灵动移动结合的交手体验。
其中,攻击的长度观察为1-4个完整招式,而空窗期通常为一次闪避位移。
- 招式没有复读,CD是?
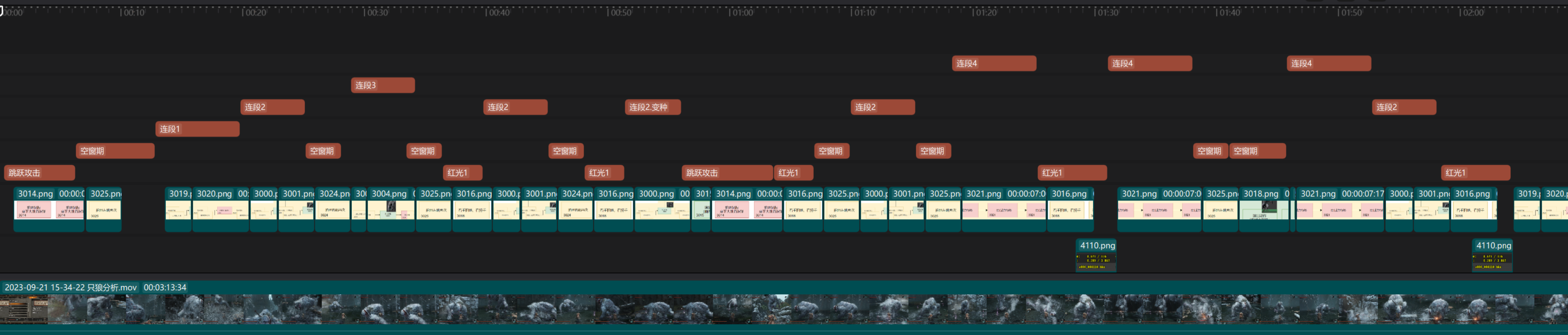
将招式分别拆开,我们会发现同个招式没有连续两次出现的情况。观察两个招式之间的最短间隔时长(从上一个末尾到下一个的开始):
| 标注 | 最短时间间隔约 | 动画 |
|---|---|---|
| 连段1 | 3019;3020 | |
| 连段2与变种 | 6 | 3000;3001 |
| 连段3 | 3003;3004 | |
| 连段4 | 6 | 3021 |
| 跳跃攻击 | 50 | 3014 |
| 红光1 | 9 | 3016 |
| 空窗期 | 5 | 四方向闪避位移 |
用行为树的简单拟合
总结一些关键结论:
- 攻击行为与空窗期相间
- 攻击行为自身有间隔
我们可以使用行为树对这个出招序列进行一个简单的拟合:
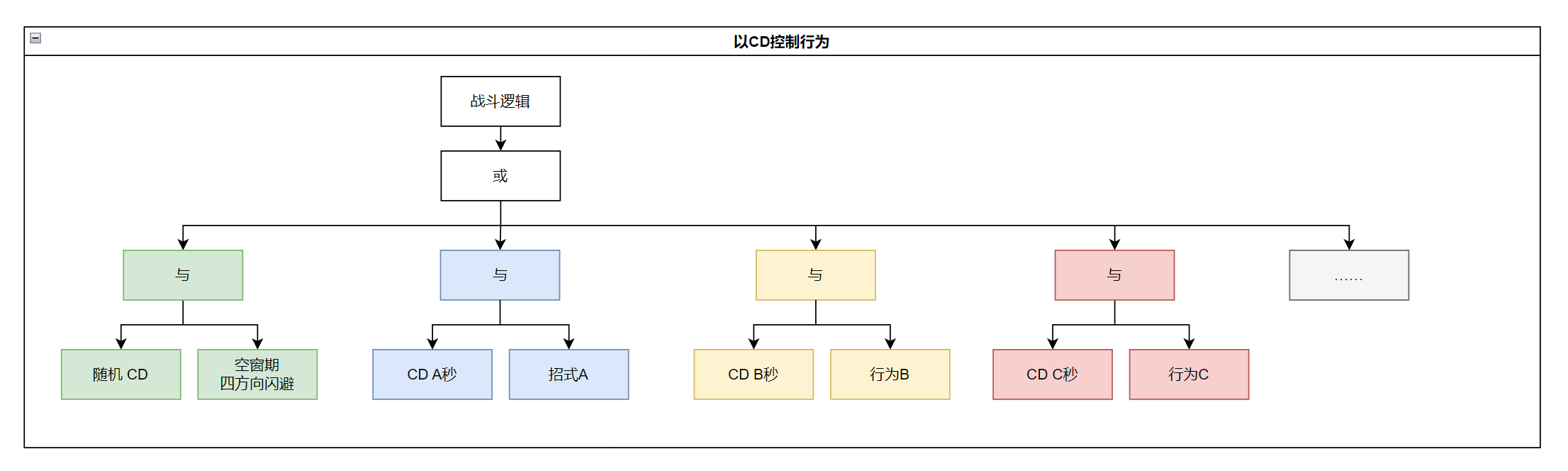
这个决策逻辑逻辑看起来很简单,因为这段战斗也只是一个局部序列,有着一定的局限性,不过还是做一个思考练习,如何让这个逻辑变得更好?
- 与战斗进程挂钩的空窗间隔
简单来说,通过控制空窗期的CD来控制玩家的战斗压力,结合一个能反映玩家战斗进程的数值——比如血量或者时间,就可以形成差异化的心流体验或者战斗历程。
- 更加复杂且细致的条件
和上面的思路类似,我们可以为不同的技能设置除了CD以外更加细致的条件,比如关联自身血量,对于只狼来说,基础重要属性还有自身的架势槽;对于一个常规的动作游戏,还可以关联敌我的空间位置关系等条件。
- 攻击前的调整位置
对于一个动作游戏,招式的适用打击距离,一般是有限的。比如一个前冲拳,能冲的距离可能最多4米,那么对于4米外的目标,可能就需要先靠近目标再释放,不然就会形成空挥的体验(当然,空挥也是一种体验!)。对于4米内过近的目标,可能也需要先远离,避免一些不好的表现。
这部分可以通过设置招式前的距离检测来避免。这些检测相应的也会造成限制从而降低释放的可能性,这是一个取舍问题。
小结:一定收获但局限
以传统而经典的行为树配置方法的话,对狮子猿AI的分析大致如上所述。当然,文章的长度已经出卖了作者,下文才是本次分析的重点,但是上文所叙述一些经典分析方法乃至思路也是相当重要的。
那么话不多说,我们来看看拆包/反编译后的狮子猿AI的LUA脚本。
基于LUA的架构设计
本部分我们讨论一些宏观架构相关的话题,有时会使用行为树来对比,方便理解两者之间使用和思维的差异性。
本节的目标是通过对架构的分析,带来一些思路的启发,从规则层面改善AI编写的效能。
决策与逻辑分离
拆包后的lua文件大致如下所示:
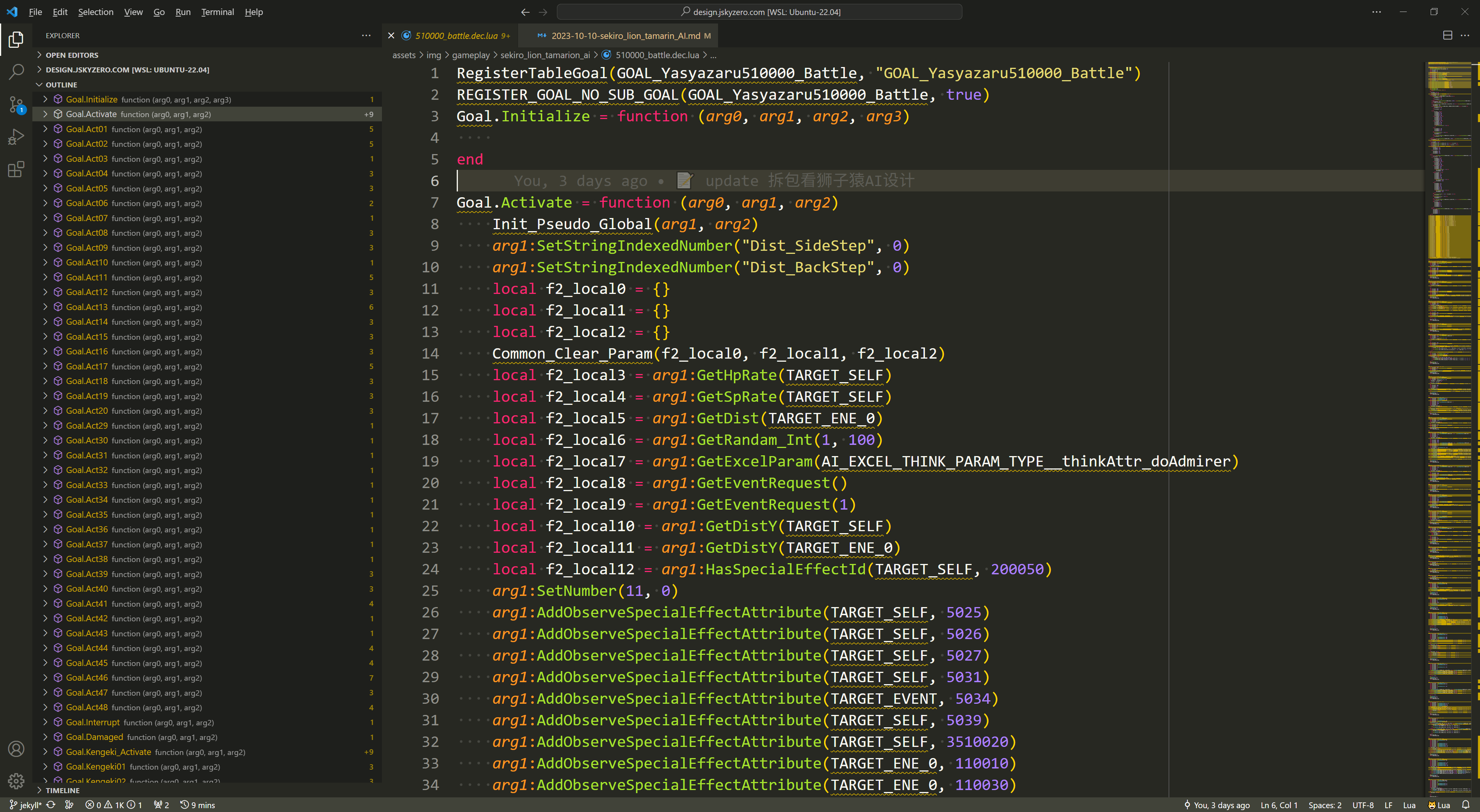
原始内容可以参考:狮子猿 510000_battle.dec.lua,后文部分内容涉及到蝴蝶夫人 509000_battle.dec.lua
最外层是若干函数,如下图所示这里将其分了四类,具体的逻辑我们将在第三部分展开叙述。

和传统的行为树比,有一个非常具体的区别,只狼(或者说FromSoftware的游戏)的AI是将主决策逻辑和行为逻辑分开的。比如上图所示的Activate函数里面是主决策逻辑,里面会在一定条件下调用不同的ActXX系列函数。
这样做有什么好处呢?我认为是高效复用和分离逻辑。
高效复用
先从高效复用说起,在行为树的语境里,如果在两个地方都需要同一段逻辑,最简单的方法是直接拷贝一串逻辑过去,这样会很简单,但是问题就是,下次修改时,容易遗漏,或者出其他差错。
相对完善的方法是,编写一个AI子树,去定义一些传递的黑板变量,但是这个操作的成本就会变高,普遍需要管理独立的新文件,增加心智上的负担。
而使用脚本语言,则可以利用编程语言自带的函数的语法,来高效实现这一过程。(这里并不是说使用LUA脚本,就比行为树要好,只是各自有不同的特点。)

分离逻辑
另一个话题则是分离逻辑,如果你配置过复杂AI的话,应该能理解AI设计的核心问题之一,就是解决复杂度的问题,这需要工程学的方法、可扩展且表达力强的通用架构、编写时符合直觉的逻辑思路等等……
将问题划分、以大化小的分治法也是核心思路之一,将行为逻辑和决策逻辑分开,能让双方聚焦各自的问题:决策逻辑负责复杂的条件检测,调用行为;而行为逻辑则只解决一个具体行为的实现,这里也可能会有一定的条件检测。但是是服务于这个行为的。这样,在面对复杂逻辑时,就可以将复杂逻辑化为若干部分,分别实现,避免干扰。
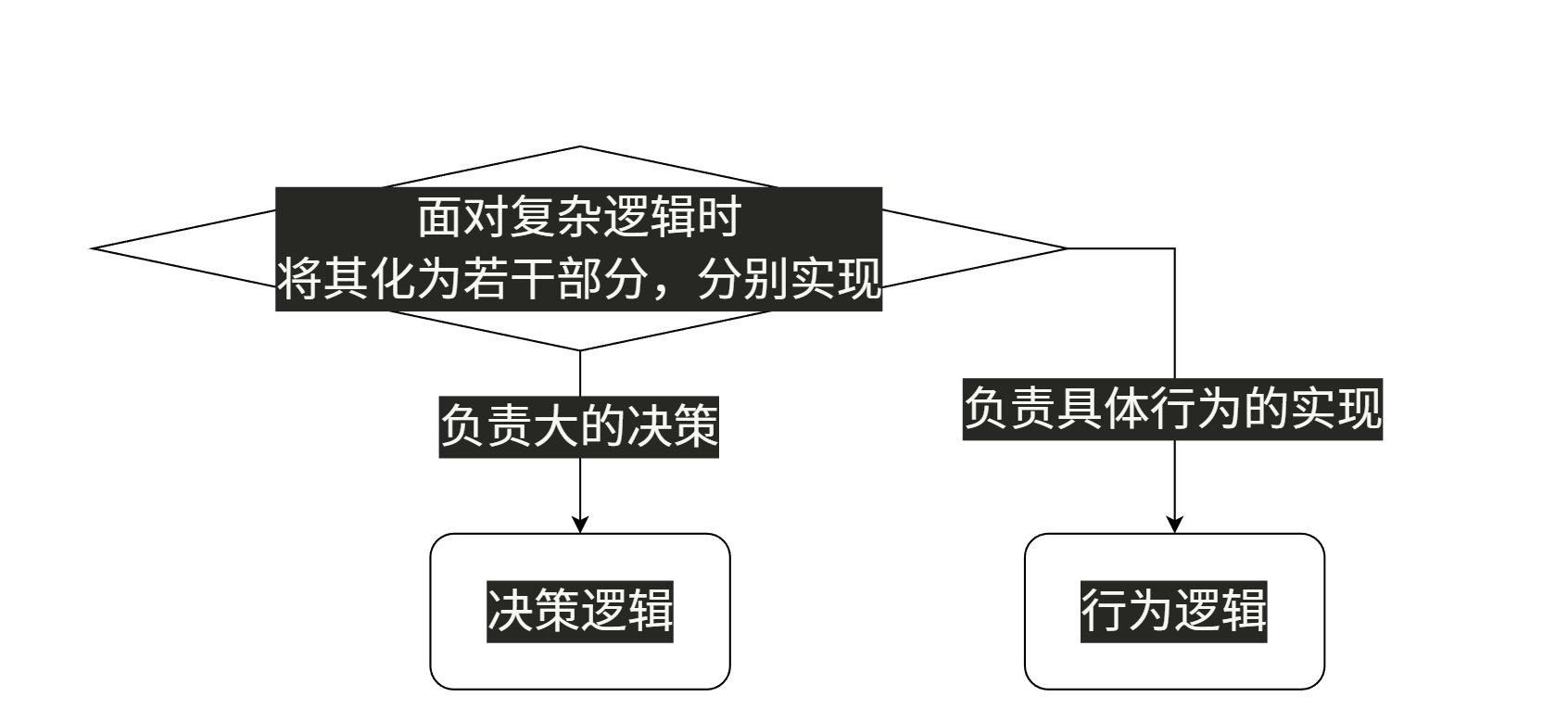
一个类似思路的、在软件工程的语境的例子是MVC架构(Model-View-Controller,模型-视图-控制器)。将软件分为:数据描述相关、处理交互视图相关、处理如何控制数据相关,三个部分各司其职,避免互相干涉带来的心智负担。
带条件检测的行为队列
本小节我们聚焦到一个具体的行为的架构设计。比如【靠近,A招式,B招式】的一个行动序列。
在行为树的语境中,会使用运行节点来描述一个耗时的行为,大概会如下图所示去实现:
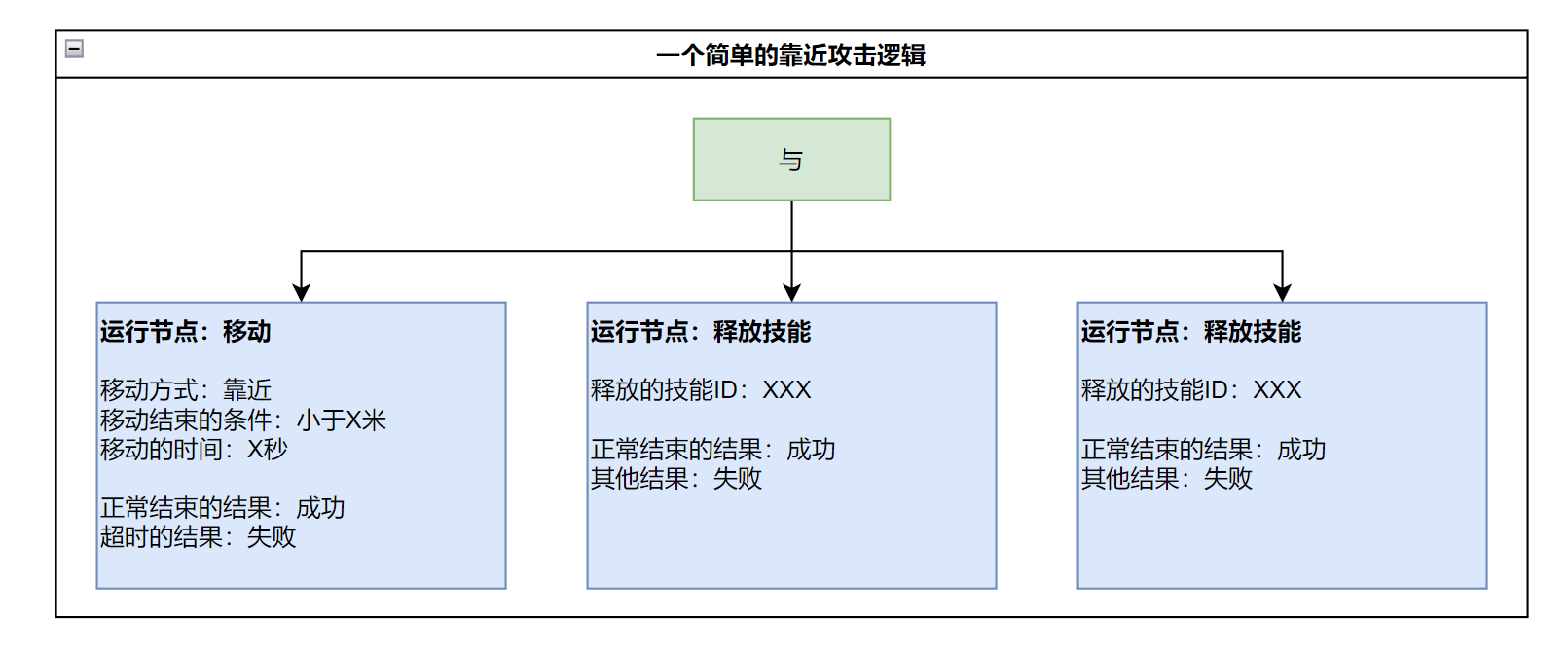
想象一下这样的命令在Lua的一个函数中应该怎样描述实现?对于单个命令,下达单个的命令指令就行,但是当涉及到一连串连续执行的命令,就会麻烦一些。
行为队列
答案是维护一个行为的“队列”,对于【靠近,A招式,B招式】这个序列,就添加靠近,A招式,B招式三个命令,等到执行的时候按照队列的先进先出的顺序挨个执行。
arg1:AddSubGoal(GOAL_COMMON_ApproachTarget, f3_local4, TARGET_ENE_0, f3_local1, TARGET_SELF, f3_local3, -1)
arg1:AddSubGoal(GOAL_COMMON_ComboTunable_SuccessAngle180, 10, f3_local5, TARGET_ENE_0, 999, 0, 0, 0, 0)
arg1:AddSubGoal(GOAL_COMMON_ComboRepeat_SuccessAngle180, 10, f3_local6, TARGET_ENE_0, 999, 0, 0, 0, 0)
类似下图,这是Act01行为的两个攻击的添加命令的代码和开发者工具观察实际执行的Goal队列
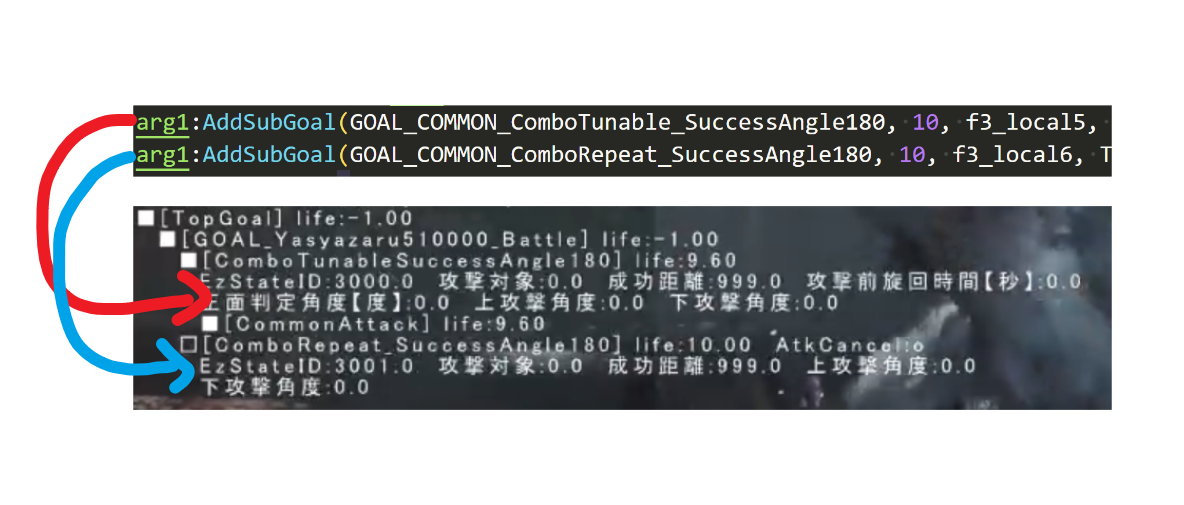
可以观察到,添加命令(或者,行动目标,这里维持统一还是使用命令这个词)时候,有非常多的参数,除了常规描述行为是啥的自身关键参数,还有一个时间参数。主要是用于避免操控的对象一致处于某个行为中,给个超时。
在只狼的架构中,这个时间在自己执行的时候才会开始倒数,还有一种做法是,在添加入执行队列就开始倒数,应该也是一种规则。
条件检测的时效性
找了一个移动和释放攻击的命令的指令,大概对应的一下参数的含义,如下图所示。

- 对于移动来说,当达到距离时则视为成功,这里是用作判断持续行为的成功结束条件。
- 而对于释放攻击来说,如果不满足释放距离则会释放失败,这里是用作开始执行的前置条件。
留意开始执行的前置条件,在添加命令的时候就可以进行一次检测,那为什么不在添加命令的时候就进行检测呢?对比下面这两个例子:
- 添加指令时检测距离
-- 添加指令时检测距离
AddGoal_BlaBla(1, 10, 9999) -- 添加释放攻击动作1、时间10秒、释放前检测9999米
if L < 5 then -- 判断距离小于5米
AddGoal_BlaBla(2, 10, 9999) -- 添加释放攻击动作2、时间10秒、释放前检测9999米
end
- 指令执行时检测距离
-- 指令执行时检测距离
AddGoal_BlaBla(1, 10, 9999) -- 添加释放攻击动作1、时间10秒、释放前检测9999米
AddGoal_BlaBla(2, 10, 5) -- 添加释放攻击动作2、时间10秒、释放前检测5米内
其实标注已经暴露了核心问题,添加指令时和指令执行时,可能不是同一时刻,而这个单独的检测选项就是解决这个问题,确保能在指令执行时,进行检测。
听起来有点像打补丁的做法,解决的核心问题是:决策进行的瞬间,一次性可能添加了很多动作序列;序列靠后被执行的单个动作,轮到它的时候,前置条件已经失去了意义。
在行为树的语境中其实不存在这个问题,运行节点会完美过渡时间,轮到这个节点执行前才会真的进行这个节点的检测,但也可能,就是因为这种模糊性,会带来类似“空挥”的体验,这里不再展开讨论了。
其他架构逻辑
这里讨论一些其他的、用于逻辑表达的小设计。
行为概率与行为CD
前面我们提到过,由决策逻辑调用行动逻辑的函数:
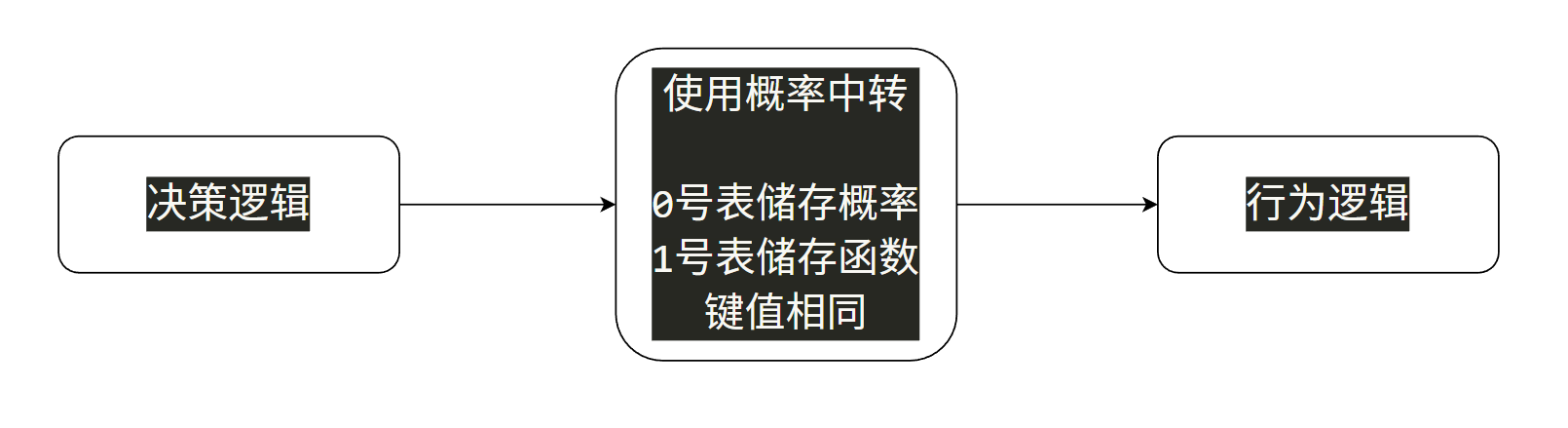
但是这个过程还是挺有意思的,并没有直接去调用函数,而是使用概率做中转,再去调用对应的函数。
-- 首先整了几个“表格”做中转
local f2_local0 = {}
local f2_local1 = {}
local f2_local2 = {}
-- 当决策的时候,
-- 将X号行为的发生概率储存到,0号表格,Key为X的值里
if f2_local5 >= 18 then
f2_local0[6] = 50
f2_local0[15] = 800
f2_local0[18] = 50
f2_local0[19] = 50
f2_local0[43] = 100
elseif f2_local5 >= 12 then
-- ...
elseif f2_local5 >= 5 then
-- ...
end
-- 检查冷却,如果不满足,概率直接打到1
f2_local0[1] = SetCoolTime(arg1, arg2, 3000, 15, f2_local0[1], 1)
f2_local0[2] = SetCoolTime(arg1, arg2, 3003, 15, f2_local0[2], 1)
-- ...
f2_local0[46] = SetCoolTime(arg1, arg2, 3005, 10, f2_local0[46], 1)
-- 将X号行为的函数储存到,1号表格,Key为X的值里
f2_local1[1] = REGIST_FUNC(arg1, arg2, arg0.Act01)
f2_local1[2] = REGIST_FUNC(arg1, arg2, arg0.Act02)
-- ...
f2_local1[48] = REGIST_FUNC(arg1, arg2, arg0.Act48)
-- 最后调用,根据0号表格的概率调用 1号表格储存的函数行为
-- 此处函数完整内容可参考
-- aicommon-luabnd-dcx\script\ai\out\bin\common_battle_func.dec.lua
Common_Battle_Activate(arg1, arg2, f2_local0, f2_local1, f2_local13, f2_local2)
如果上面的内容稍微有点复杂,没关系,举个具体的例子:
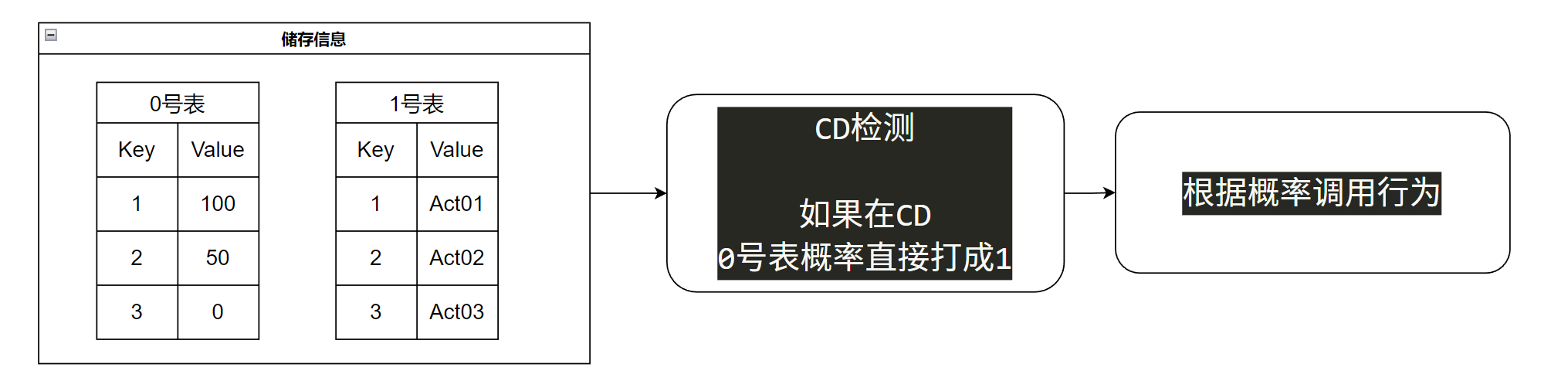
在某个情形下,如果我们决定使用Act01和Act02行为,且概率为100:50,那么我们并不会直接进行随机数的比较后调用函数,而是会将概率储存下来,同时将行为也储存下来,两者维持下标相同。这样脱钩后,甚至还可以进行一次CD的检测,如果不满足CD,则可以直接将概率打到最小,(为1不为0也处理了所有行为都CD时,至少可以随机出结果。)最后,再根据概率去调用对应的行为。
这样做的好处是显而易见的,它允许我们将可用性检测——比如CD或者其他规则,放在决策之后,一方面保证了可用性的筛选,另一方面也避免了先进行可用性检测的麻烦,甚至概率为1而不为0的小细节,也覆盖了全部行为都在CD的边界情况。
在行为树的语境中,先进行可用性检测可以使用封装了自规划的算法的节点,选取可用性最高的行为。
在实际的工作中,有时没有规划算法的节点,最常见的情形和解决是,检测到攻击仍然处于CD,干脆失败向后决策,用发呆来作为保底。
信息感知与标记BUFF
对于一个动作游戏的AI,除了常规的HP、MP、位置等信息,对于敌我动作状态的检测逻辑应该会很多,动作游戏嘛,玩的就是动作之间的规则。
只狼也不例外,一些信息的获取、判断如下所示:
-- Goal.Activate 局部变量
local f2_local3 = arg1:GetHpRate(TARGET_SELF)
local f2_local4 = arg1:GetSpRate(TARGET_SELF)
local f2_local5 = arg1:GetDist(TARGET_ENE_0)
local f2_local6 = arg1:GetRandam_Int(1, 100)
local f2_local7 = arg1:GetExcelParam(AI_EXCEL_THINK_PARAM_TYPE__thinkAttr_doAdmirer)
local f2_local8 = arg1:GetEventRequest()
local f2_local9 = arg1:GetEventRequest(1)
local f2_local10 = arg1:GetDistY(TARGET_SELF)
local f2_local11 = arg1:GetDistY(TARGET_ENE_0)
local f2_local12 = arg1:HasSpecialEffectId(TARGET_SELF, 200050)
-- Goal.Activate 变量检测
elseif not not arg1:HasSpecialEffectId(TARGET_ENE_0, 110060) or arg1:HasSpecialEffectId(TARGET_ENE_0, 110010) then
f2_local0[39] = 100
elseif Common_ActivateAct(arg1, arg2) then
总结归纳一下,常规的信息大致包括这些:
- 属性类
- HP
- SP
- 固有Excel变量
- 空间类
- 敌我距离
- 距地面高度
- 敌我角度
- 障碍物检测
- 随机类
- 随机整数
- 随机小数
而关于动作的检测,除了一些经过封装的函数或者事件,大部分都是用标记BUFF实现的。
一个很典型的例子是蝴蝶夫人的弹反动作,左方向8400,右方向8401,分别添加了200211和200210,两个不同的标记异常状态,这样AI就可以通过检测对于的标记buff,来知道是蝴蝶夫人是在左弹还是右弹。
再进一步,可以根据左右弹设计不同的出招逻辑:
-- 509000 蝴蝶夫人
-- Goal.Kengeki_Activate 逻辑判断
elseif f48_local0 == 200210 then
if f48_local4 >= 4 then
f48_local1[50] = 100
elseif SpaceCheck(arg1, arg2, 180, 4) == false then
f48_local1[6] = 20
f48_local1[10] = 80
else
f48_local1[1] = 15
f48_local1[9] = 15
f48_local1[10] = 100
end
elseif f48_local0 == 200211 then
if f48_local4 >= 4 then
f48_local1[50] = 100
elseif SpaceCheck(arg1, arg2, 180, 4) == false then
f48_local1[6] = 40
f48_local1[10] = 60
else
f48_local1[1] = 40
f48_local1[9] = 20
f48_local1[10] = 60
end
猜测接口上,除了自己给自己加标记buff,应该也是可以定向给敌人加的。
小结一下:以标记buff作为检测动作的中间层,可以一定程度上让逻辑与具体的Action检测脱钩,避免AI与动作的强耦合,带来修改时的麻烦。但是也会需要buff自身是一个简单易用、高效的功能。
计时器/角色变量/事件与打断
这里是发现到的一些适用于逻辑编写的功能。
- 计时器
上文提到CD其实也是一种计时器,有些时候如果要控制指定逻辑出现的间隔,就可以使用计时器,大概有以下功能:
-- 开始计时,参数1是记时器的编号,参数2是计时器的倒计时时间
arg0:SetTimer(2, 8)
-- 比较指定计时器的现在的记时
arg1:GetTimer(10) > 0
-- 检测指定计时器的记时是否结束
arg1:IsFinishTimer(3) == true
只狼的计时器大概是只有16个,事实上也足够了。
- 角色变量
使用角色变量可以方便的在不同逻辑之前储存信息、检查信息:
-- 设置指定变量到指定值
arg1:SetNumber(11, 0)
-- 设置指定变量自增
arg1:SetNumber(2, arg1:GetNumber(2) + 1)
-- 检测指定变量的值
arg1:GetNumber(1) == 1
之前在哪里看到过好像4号变量和弹刀有关,记不清了,可见有些变量应该是全角色通用、有统一含义的。
变量的槽位好像也是16个,和计时器一样,固定数目一方面一般不会达到上限,另一方面也可以保证实现起来较为简单、性能开销较为可控。16这个数值感觉是个可参考值。
- 事件与打断
严格意义上感觉不能叫事件,或者叫监听?当发生一些事件时,就会打断原有决策,重新进行打断决策。
-- 添加区域监听
arg0:AddObserveArea(0, TARGET_SELF, TARGET_ENE_0, AI_DIR_TYPE_F, 360, 8)
-- 删除区域监听
arg1:DeleteObserve(3)
-- 判断打断类型:在区域外打断
arg1:IsInterupt(INTERUPT_Outside_ObserveArea)
-- 添加Buff监听
arg1:AddObserveSpecialEffectAttribute(TARGET_SELF, 5025)
-- 判断打断Buff类型
arg1:GetSpecialEffectActivateInterruptType(0) == 5039
-- 处理打断
Goal.Interrupt = function (arg0, arg1, arg2)
-- ...
-- 打断后检测使用道具!药检.jpeg
if Interupt_Use_Item(arg1, 5, 10) then
arg1:Replanning()
return true
end
-- ...
end
在打断的逻辑里面看到了使用道具,合理推测这就是传说中的药检的逻辑。
事件与打断为AI提供了一种针对环境的变化快速反应的能力——反应性,合理使用这部分机制,可以让AI更加生动。但这部分逻辑如果过于“单薄”,也会很容易被玩家利用。
封装
前面提到过解决复杂度的问题,是游戏AI的核心问题之一,封装也是一种有效的方法,它可以有效提供逻辑的复用。
只狼中大部分封装的逻辑都在aicommon-luabnd-dcx\script\ai\out\bin\目录,大概分为以下几类:
- 常量类:比如
ai_define.dec.lua、logic_list.dec.lua,
构成:里面定义了一堆常量变量
功能:当枚举值用,增加可读性
- 具体行为类:比如
approach_on_failed_path.dec.lua
构成:描述一个行为的过程,里面分为Activate、Update、Terminate、Interupt几个部分
功能:大概可以分为移动、攻击、功能三大类
- 辅助函数类:比如
common_battle_func.dec.lua
构成:直接以函数的语法编写一些函数
功能:提供编写逻辑的一些便利性
理论上来说,好的封装是成功的一半,能极大降低新AI编写的工作量。
小结:思路与格局打开
本节讨论了相当多的思路、机制上的东西,使用这些“手法”,可以解决非常多的问题。
在这一节结束的时候想重新强调,“使用成本”这个话题,很多时候应该尽可能的降低使用成本,减少中间环节。比如申明一个Buff这样基础的操作,如果成本增加——比如步骤多一步,时长增加5秒,由于行为处于基层位置,很可能对最后产生指数级别的时长影响。
感受与细节设计
讨论了很多“虚”的东西以后,本部分我们讨论具体的狮子猿AI逻辑,着重分析行为逻辑和对应的感受。
思考了很久这部分应该如何去呈现,最后的结论是还是一条一条过一遍。也方便读者感受一个真实的AI是什么样子的。
行为逻辑
本来是打算先说决策逻辑的,后来发现如果不看行为看决策会一头雾水,所以这里先从行为开始看起。
一共40个具体行为,有一部分后续的决策中没有使用。这里按照动画之前行为的感受初步划分:黄色为花里胡哨、红色为高危记忆点、绿色演出性质,总览整理如下:
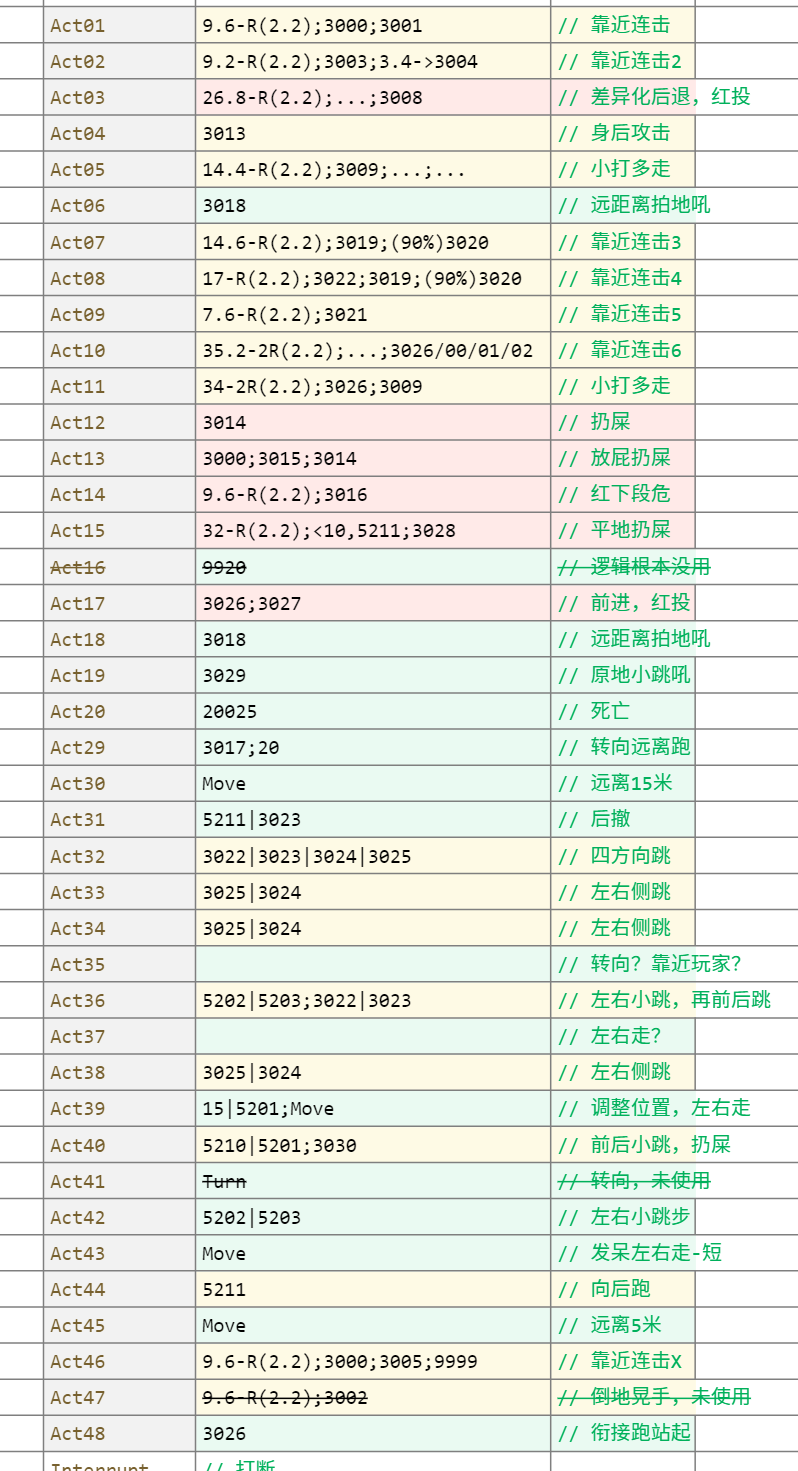
这里也录制了1-20号行为的演示视频,末尾还有一段战斗过程的切片,可以参考Bilibili 狮子猿 AI行为演示
接下来我们挑一些行为具体看看:
Act01 9.6-R(2.2);3000;3001
一些没用到的变量这里就直接删掉了,精简后如下:
Goal.Act01 = function (arg0, arg1, arg2)
local f3_local0 = arg0:GetDist(TARGET_ENE_0)
local f3_local1 = 9.6 - arg0:GetMapHitRadius(TARGET_SELF)
local f3_local4 = 5
if f3_local1 < f3_local0 then
arg1:AddSubGoal(GOAL_COMMON_ApproachTarget, f3_local4, TARGET_ENE_0, f3_local1, TARGET_SELF, f3_local3, -1)
end
local f3_local5 = 3000
local f3_local6 = 3001
arg1:AddSubGoal(GOAL_COMMON_ComboTunable_SuccessAngle180, 10, f3_local5, TARGET_ENE_0, 999, 0, 0, 0, 0)
arg1:AddSubGoal(GOAL_COMMON_ComboRepeat_SuccessAngle180, 10, f3_local6, TARGET_ENE_0, 999, 0, 0, 0, 0)
arg0:SetNumber(5, 1)
GetWellSpace_Odds = 0
return GetWellSpace_Odds
end
这部分逻辑还是挺简单的,大概的意思是调整位置,放俩攻击。
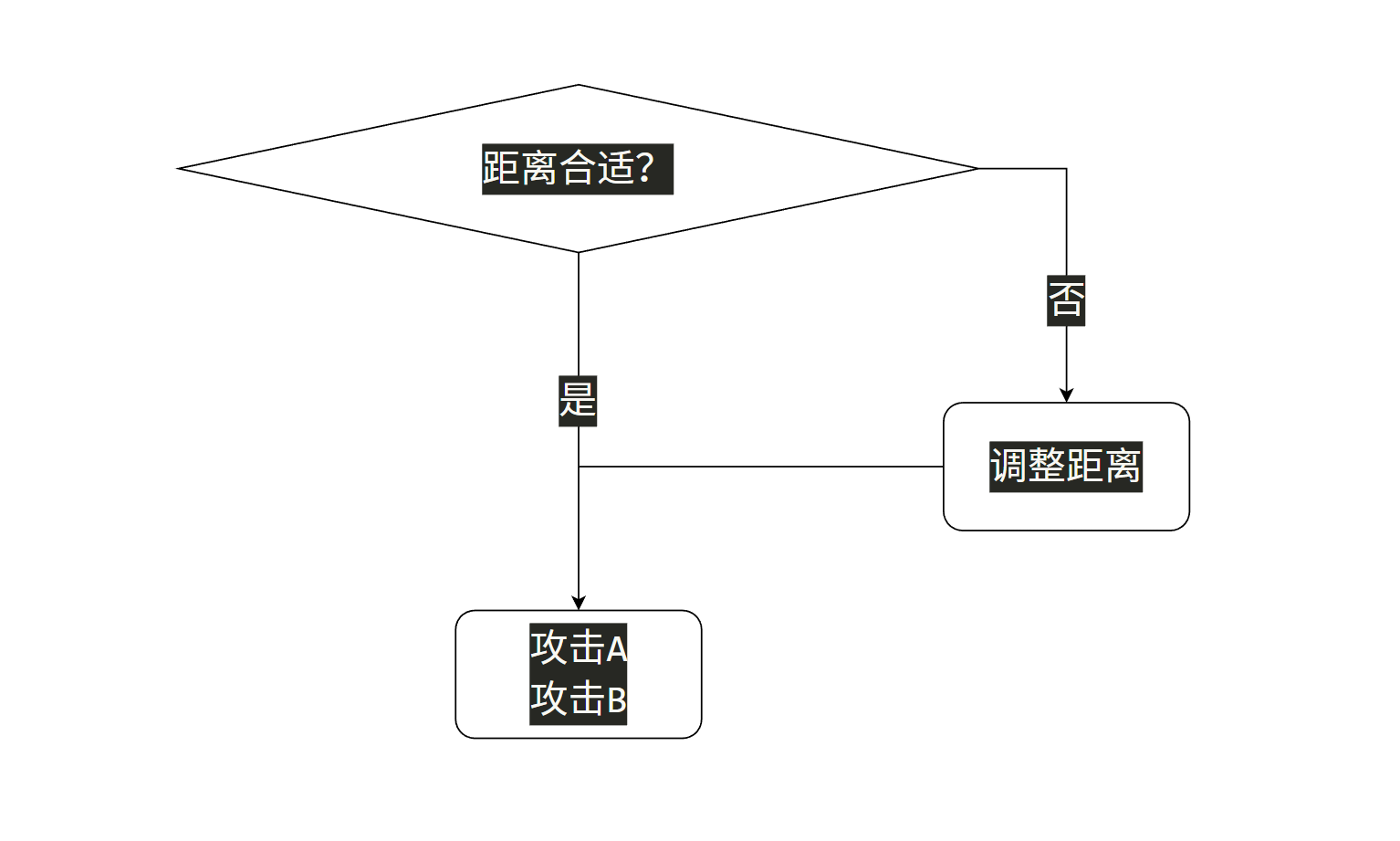
虽然简单,但是基本上所有的行为都是这个的简化或者复杂化,后面的行为也会以这个为模板展开说明。
说一些中间有意思的点:
- 距离比较与狮子猿半径
之前简要标注的时候写的是9.6-R(2.2);3000;3001,后面俩是招式名字,为啥前面写的是9.6-R呢?
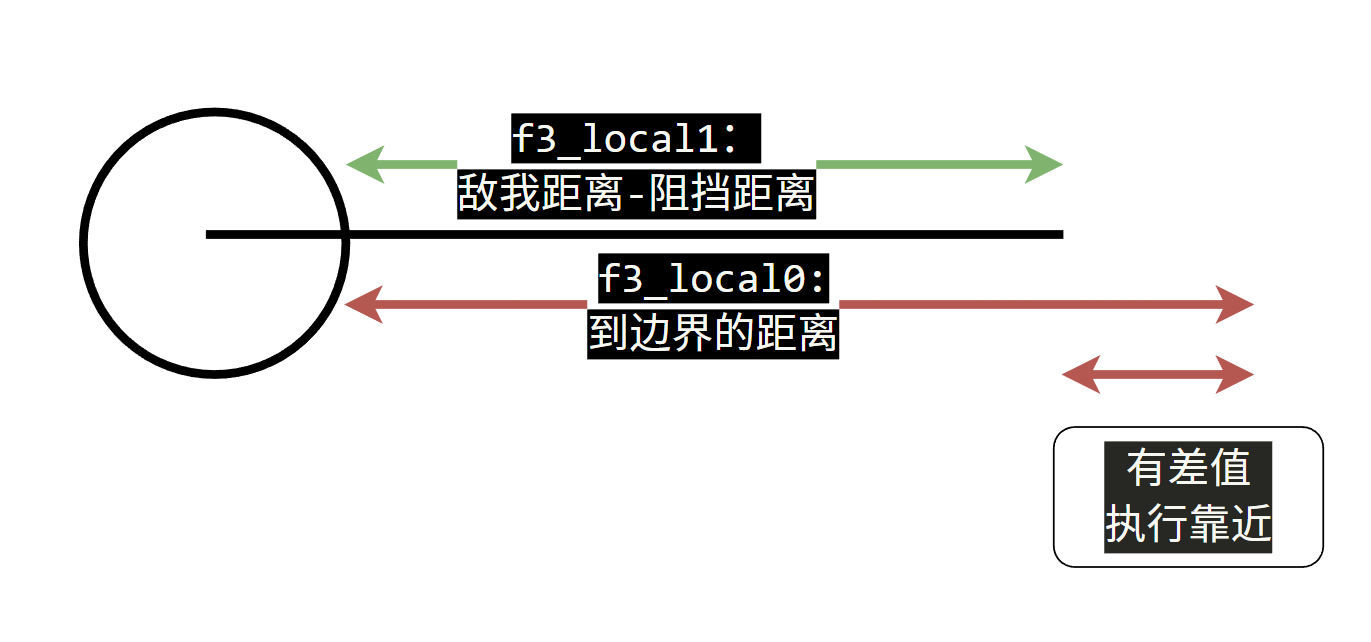
画了一个图方便理解,用于与敌我距离进行比较的值,是固定值减去了自身半径的值,也就是说只狼中敌我距离的计算是计算到阻挡外边缘的,由于这个值同时用到了后面的靠近逻辑中的目标值,我们可以反向算出狮子猿猴的半径是2.2米,于是有了上面这个标注。
- 运行时检测之距离不敏感
后面两个攻击的检测距离都是999,前面架构方面有提到相关的东西,这里就是一个会空挥的、距离不敏感的例子。
Act02 9.2-R(2.2);3003;3.4->3004
Act02和Act01的区别除了换了招式和距离,另外就是释放时是距离敏感的,太远就不会放了。
Goal.Act02 = function (arg0, arg1, arg2)
local f4_local0 = arg0:GetDist(TARGET_ENE_0)
local f4_local1 = 9.2 - arg0:GetMapHitRadius(TARGET_SELF)
local f4_local2 = false
local f4_local3 = 10
if f4_local1 < f4_local0 then
arg1:AddSubGoal(GOAL_COMMON_ApproachTarget, f4_local3, TARGET_ENE_0, f4_local1, TARGET_SELF, f4_local2, -1)
else
end
local f4_local4 = 3003
local f4_local5 = 3004
local f4_local7 = 9.2 - arg0:GetMapHitRadius(TARGET_SELF)
local f4_local8 = 5.6 - arg0:GetMapHitRadius(TARGET_SELF)
local f4_local9 = 0
local f4_local10 = 0
arg1:AddSubGoal(GOAL_COMMON_ComboAttackTunableSpin, 10, f4_local4, TARGET_ENE_0, f4_local7, f4_local9, f4_local10, 0, 0)
arg1:AddSubGoal(GOAL_COMMON_ComboFinal, 10, f4_local5, TARGET_ENE_0, f4_local8, f4_local9, f4_local10, 0, 0)
arg0:SetNumber(5, 1)
GetWellSpace_Odds = 0
return GetWellSpace_Odds
end
这里的3003的这个前置距离检测,其实可以不用检测,因为上面刚刚执行了靠近,两个距离数值一样,且中中间没有时间差。
Act03 26.8-R(2.2);…;3008
这应该是第一个稍微复杂的逻辑,和之前思路是类似的。
Goal.Act03 = function (arg0, arg1, arg2)
local f5_local0 = arg0:GetDist(TARGET_ENE_0)
local f5_local1 = 26.8 - arg0:GetMapHitRadius(TARGET_SELF)
local f5_local2 = false
local f5_local3 = 10
-- 太远靠近
if f5_local1 < f5_local0 then
arg1:AddSubGoal(GOAL_COMMON_ApproachTarget, f5_local3, TARGET_ENE_0, f5_local1, TARGET_SELF, f5_local2, -1)
-- 太近远离1
elseif f5_local1 - 8 < f5_local0 then
arg1:AddSubGoal(GOAL_COMMON_AttackTunableSpin, 4, 3023, TARGET_ENE_0, SuccessDist1, TurnTime, FrontAngle, 0, 0)
-- 太太近远离2
elseif f5_local1 - 24 < f5_local0 then
arg1:AddSubGoal(GOAL_COMMON_SpinStep, StepLife, 5211, TARGET_ENE_0, TurnTime, AI_DIR_TYPE_F, CourseLong)
else
-- 太太太近远离并直接中断
arg1:AddSubGoal(GOAL_COMMON_AttackTunableSpin, 4, 3023, TARGET_ENE_0, SuccessDist1, TurnTime, FrontAngle, 0, 0)
return false
end
local f5_local4 = 3008
local f5_local5 = 26.8 - arg0:GetMapHitRadius(TARGET_SELF)
local f5_local6 = 0
local f5_local7 = 120
-- 检测阻挡相关
if arg0:IsExistMeshOnLine(TARGET_SELF, AI_DIR_TYPE_F, 15) then
arg1:AddSubGoal(GOAL_COMMON_ComboTunable_SuccessAngle180, 15, f5_local4, TARGET_ENE_0, 9999, f5_local6, f5_local7, 0, 0)
else
return false
end
GetWellSpace_Odds = 0
return GetWellSpace_Odds
end
简单来说,在执行一个有很长一段靠近前摇的抓取攻击前,有一些差异化的自定义远离逻辑。(也侧面说明了前面的俩行为是只管玩家和怪物过远、不管过近的,默认近是可以兼容的)
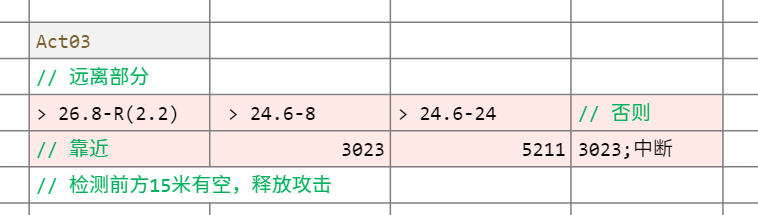
此外,这里还第一次出现了空间障碍相关检测,后面也可以看到,只狼里面有相当多的、细致的空间检测,以避免不合适的行为——比如怼墙走等行为。
Act04 以后
后面我们就不逐一展开说了,有兴趣的同学可以去看原始文件。
这里我们给出一个将行为放到状态机上的联动图,可以点开查看大图:
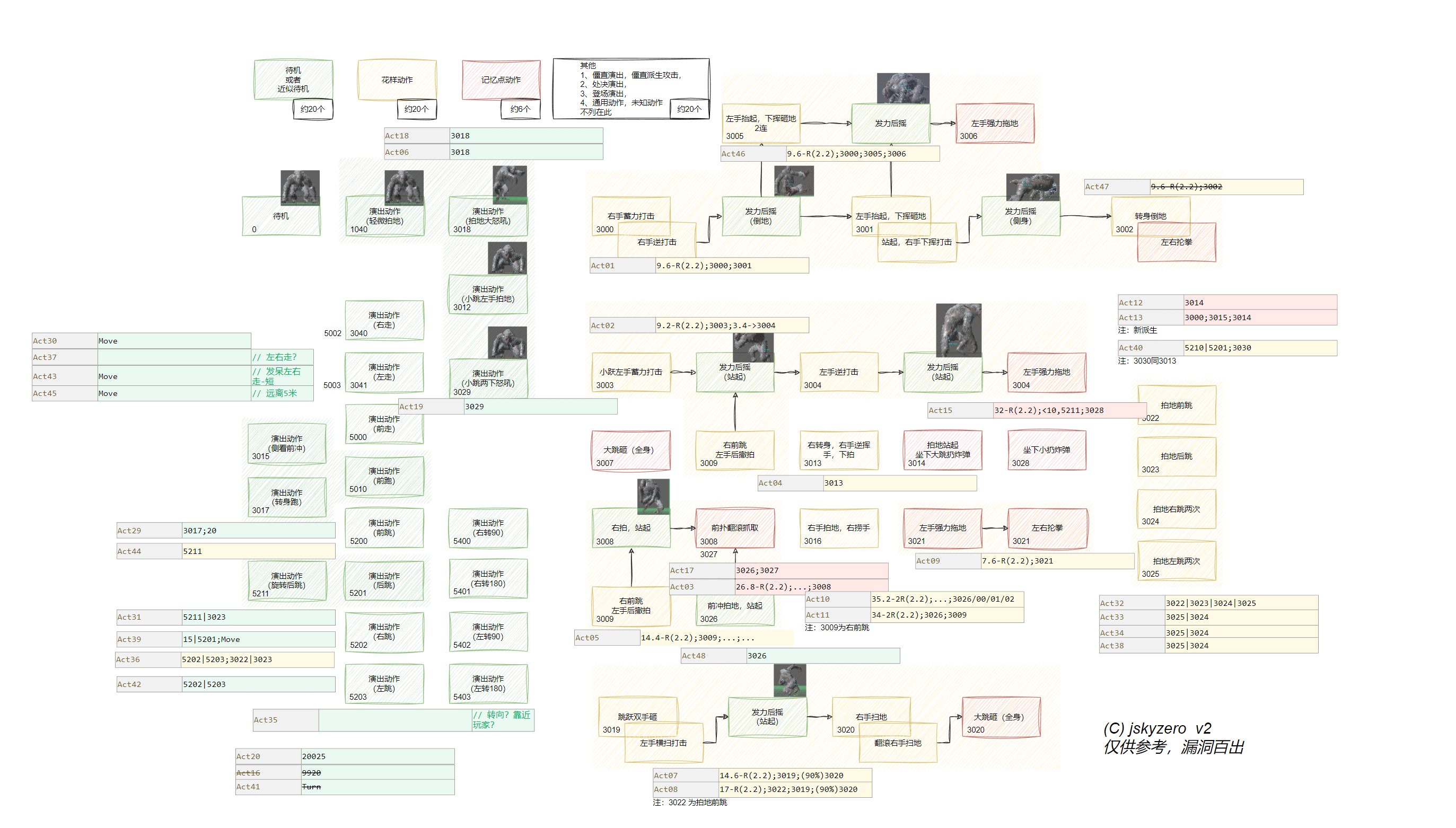
简要小结
简单总结下:
- 微观的基本范式:靠近+攻击
除了原地直接放的招式,大部分都是靠近后攻击,再在此基础上进行距离敏感、调整位置、随机变招、距离决策等行为的丰富逻辑。
- 宏观攻击感受的营造:短而密
大部分的连招都是2个攻击动作——当然具体的攻击Hit数可能不止,最多也就是3个,并没有之前分析中的超超超长连招。
但是,攻击的构成是非常密的,应该只有两处刻意发呆对峙,以此来营造战斗的持续压迫感。
- 唯一指定未使用动作:3007
整个AI里面未发现使用3007的行为,但是实际体验中记得还是会出现。可见在目前AI的范围之外,应该还是有一些动作自动跳转之类的逻辑的。
主决策逻辑
决策部分,分成三个部分方便理解:
前置行为
正如架构篇所讨论的,在主决策逻辑的一开始是一些初始化工作,大致如下图所示:
- 获取一些信息储存到变量

- 添加一些Buff的监听。
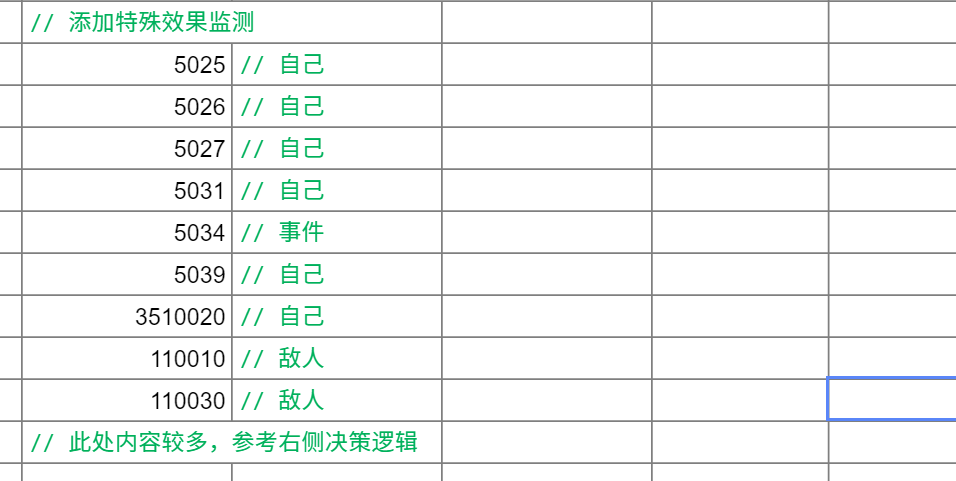
决策部分-外围
然后就开始了具体的决策部分:

最外围,这里认为是一些针对特定情况立刻做出反应的逻辑,一共10个。

- 立刻反应:死亡
比如动作20其实是死亡结算动作,可见这个事件应该就是检测死亡(或者检测转阶段)。大部分逻辑都可以通过行为去揣测检测条件的含义,部分不知道是啥的也不乱猜了。

- 特殊情况:距离太远
稍微有点意思的是处理距离过远时候,用的数值是10米,10米并不不算远,所以还配合了一个标记Buff 5030。执行的行为也很有意思,是原地拍地吼,之前拆动画的时候还没有意思到,后面才想起来这个动作是可以用义手勾过去快速拉近距离的。感觉意思是:距离太远,直接勾引你过来。你不来,我再主动靠近。
- 特殊情况:处于背后
另外一个类似的特殊检测是在玩家背后,其实这里感觉是玩家在狮子猿背后?
这里有两个需要注意的,其一是这些行为都是挑选出来的可以有转向过程能自然转向覆盖打到玩家的。
其二是这里先进行了一个距离划分,10、11、42比较普通,重点是7米内时还会有一个专门打身后的4号行为,而且比重很大。可以认为大多情况都是4。下面我们也会看到很多以较大比重来突出主要行为的技巧。
决策部分-Event(1) 10 or 1 == 1
这里是上文第三个决策的展开,因为选项太多了所以单独陈述。
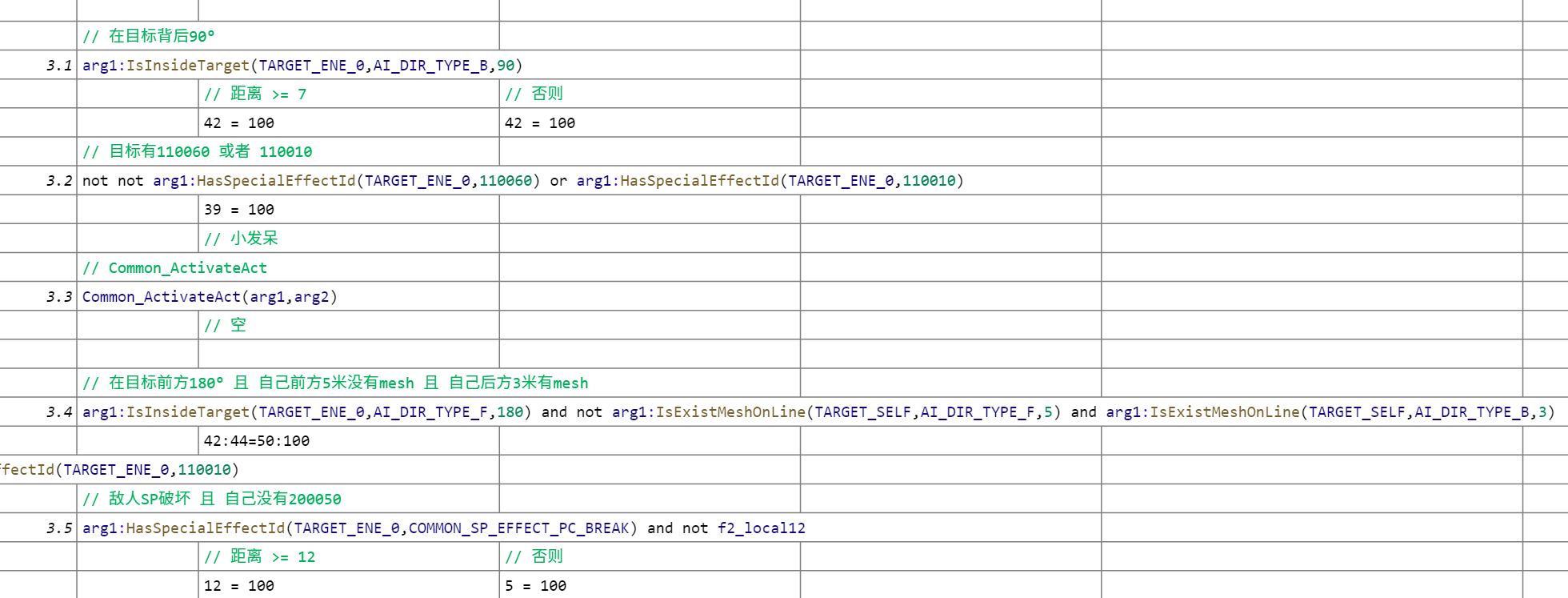
首先我们可以看到因为处于比较靠前的位置,这里仍然处理了3.1背后、3.2 & 3.3等特殊标记等情况下的行为。
并且这里还有一个检测敌人崩架势后的逻辑,远就扔屎、近就敏捷一打。

最后是一切默认情况下的攻击,也是目前看到决策最复杂的一个。粗看了一下行为,概率最高的行为分别是扔屎和下端危,似乎压力还蛮大的。
在默认情况以后,还会做一些后置检测有一个计时器和空间位置的检测。
决策部分-默认
这里就是最最最默认情况下狮子猿的出招逻辑。

首先10.1也还是进行了一些特殊情况的检测,不过由于外层就已是是最后一个检测的了,所以重复检测也没意义。

然后是默认情况的攻击行为。分得非常细,行为也很多,没有明显的特征,可以结合前面的行为含义表具体分析下。并且还有检测3号计时器完成,增加33 & 34侧跳的逻辑。
发现上面截图的时候真不能用行为:行为 = 概率:概率,很容易看错位。
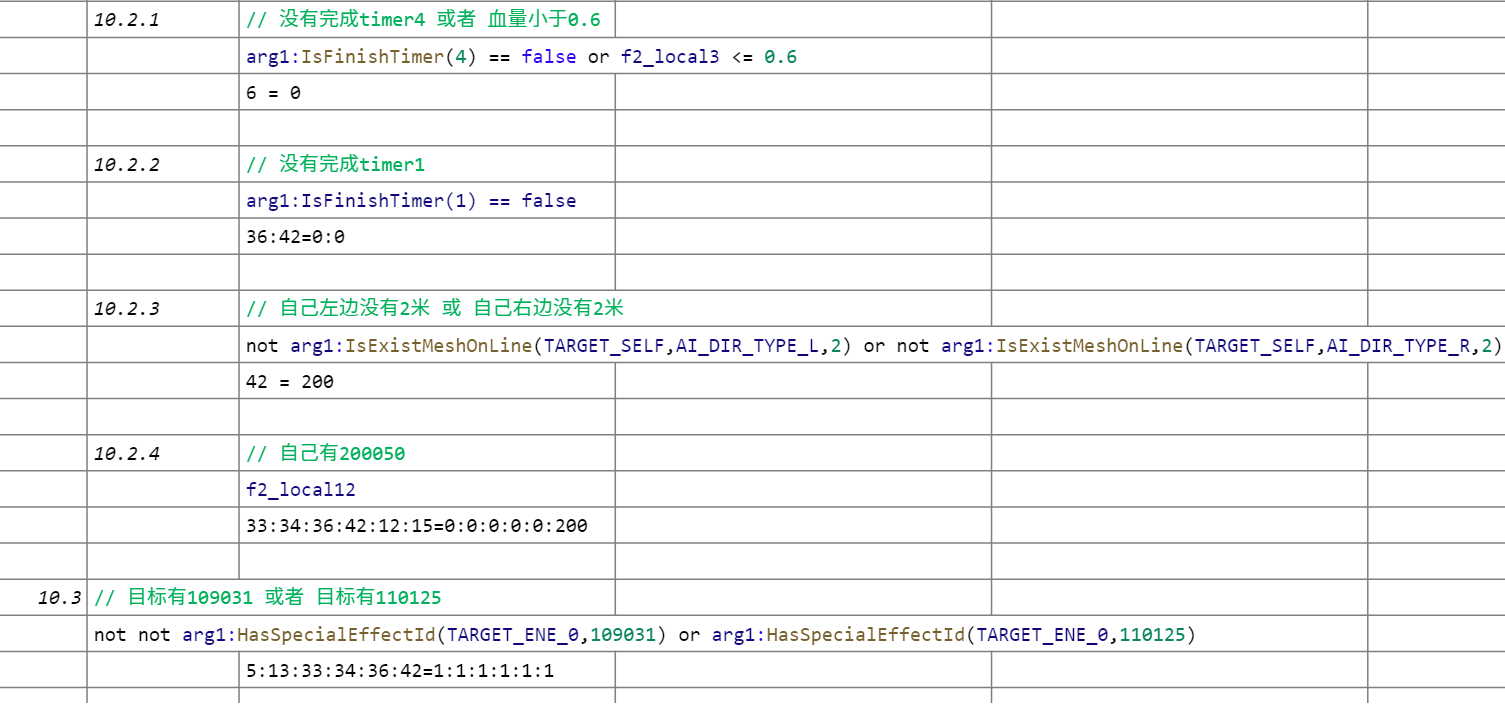
最后是一堆后置检测,比如
- 计时器4未完成 & 血量太低,关掉原地吼的概率。
- 计时器1未完成,关掉36 & 42的侧跳位移概率。
- 空间比较少,42左右小跳步
- 一些特殊标记Buff……
后置行为
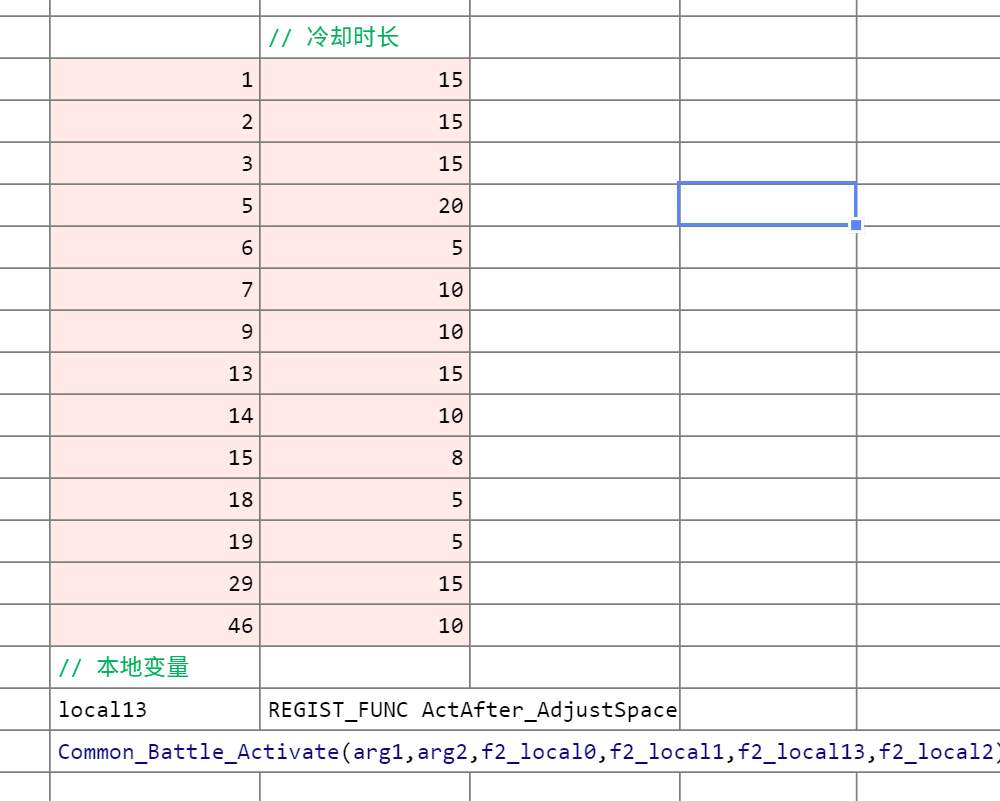
这部分也和架构篇所讨论的没啥区别,给对应的行为检测CD,如果在CD中就把概率改到最小。
应该基本都是攻击行为,似乎位移发呆之类的用单独的计时器去统计了。
剑戟(弹刀)逻辑等
狮子猿是似乎没弹刀逻辑的,狮子猿的部分逻辑如下所示

这部分参考蝴蝶夫人会比较好,就目前的了解来说,似乎是Goal.Parry负责格挡,然后Kengeki_Activate在负责根据敌我关系——主要是格挡的动作,来进行格挡派生的选择,类似上文有举到的案例,有兴趣的同学可以自行研究。
总结
对于具体行为的分析的工作量比预想中要大很多,甚至没能做到在脑海中模拟这些行为跑起来的样子。
虽然细节上做的不够,但是框架上还是盘得很明白的:
- 行为上是以【靠近、攻击】为基本模板。
- 决策上优先处理必须相应和特殊状态的行为,最后再默认行为。
- 以CD、计时器等工具再次调控行为。
全文总结
本文三个部分概述了体验层次的反推、架构设计的一些讨论、复杂的动作游戏AI的全貌,希望能对读者有所启发。
本文断断续续写了有一个月左右,文字内容很长,需要一边思考一边阅读。本文是从逆向工程出发,难免有所纰漏,欢迎指正讨论。